
O que é ETL e por que devemos integrar dados?
O digital chegou com o pé na porta e trouxe com ele um maremoto de dados para o cotidiano das empresas, o Big Data, caracterizado por um grande volume de dados, pela alta velocidade de geração desses insumos e pela imensa variedade de ativos.
Isso exigiu formas inovadoras, mais econômicas e ágeis de processamento. Para solucionar “o problema do Big Data”, surgiu o Data Science, com o objetivo de analisar, detectar padrões e transformar essa massa de dados não-estruturados em conhecimento.
Na vertente corporativa, o Business Intelligence (BI) é outra área que usa ferramentas tecnológicas para orientar decisões de negócios pautadas por evidências estatísticas e foi impulsionado por esse movimento.
Mas para que os analistas de BI tenham insumos é preciso rodar um processo de tratamento de dados para identificar problemas de coesão e padronizar dados de diversos tipos em informação homogênea.
Esse é o cerne do processo de ETL, do qual áreas como BI dependem diretamente. Continue conosco e saiba mais sobre ETL, suas etapas e importância para a integração de dados!
O que é ETL?
ETL é uma sigla que significa a junção das palavras em inglês Extract, Transform e Load. Refere-se aos procedimentos de extração, transformação e carregamento de dados para um ambiente integrado.

O ETL surge como uma estratégia para simplificar a análise de dados armazenados em um banco de dados. O processo de ETL é altamente eficiente no quesito integração de dados, estabelecendo regras de otimização e manipulação padronizada dos dados a fim de facilitar sua inserção em ferramentas ou ambientes integrados.
ETL é fundamental para empresas que desejam centralizar dados consolidados em um ambiente integrado, geralmente um Data Warehouse (DW) ou Data Mart, e é bastante versátil – pode ser aplicado tanto em banco de dados mais simples, como o SQL, até em sistemas mais complexos, como uma nuvem de Big Data.
O processo de ETL está presente em qualquer trabalho de manuseio de dados e é considerado uma fase crítica da estratégia de utilização deles. O motivo? Este é o processo responsável por garantir a qualidade com que os dados brutos serão transformados em informação relevante e que gere insights de negócios acionáveis.
Design Driven Data Science
O processo de ETL em data warehousing
De forma simples, o resultado do processo de ETL é a consolidação de dados oriundos de diversas fontes – chamadas sistemas organizacionais (OLTP) – em um data warehouse ou data mart. Mas, qual é a diferença entre um e outro?
Data Warehouse x Data Mart
Um data warehouse é, como o próprio nome diz, um repositório central de dados para orientar inteligência de mercado. Eles servem como hub que consolida dados de diversos sistemas de origem e armazena o histórico existente para análises e decisões de negócios.
O data mart funciona exatamente da mesma forma em termos de escalabilidade e modelagem de dados. Aliás, um data mart pode fazer parte de um data warehouse – ou até mesmo ser considerado um pequeno DW.
Entretanto, ambos diferem-se em suas dimensões e complexidade estrutural. Os data marts são uma configuração específica de armazenamento de dados (data warehousing), que engloba uma determinada área de assunto e oferecem informações mais aprofundadas sobre um mercado em específico. Ou seja, é um subconjunto do data warehouse, perfeito, por exemplo, para armazenar dados de um departamento.
Os procedimentos que acontecem durante o processo de ETL são fundamentais para estruturar o ambiente de armazenamento. São eles que integram e possibilitam a condução dos dados ao DW. Vale frisar que é essencial que o processo de ETL seja cuidadosamente planejado para que não comprometa os OLTPs das empresas.
Para isso, é preciso escolher a janela de operação do ETL de forma precisa, estabelecendo a periodicidade com que os dados serão sincronizados e até mesmo o alcance do processo.
Como funciona o processo de ETL?
O processo de ETL diz respeito à divisão de atividades e execução de 3 etapas lineares para o tratamento de dados: a extração, a transformação e a carga. Cada uma dessas etapas tem grande relevância para o sucesso da transição dos dados dos sistemas de origem para outro repositório de forma limpa, homogênea e integrada.
Em resumo, o processo de ETL pode ser representado pelo fluxograma abaixo:
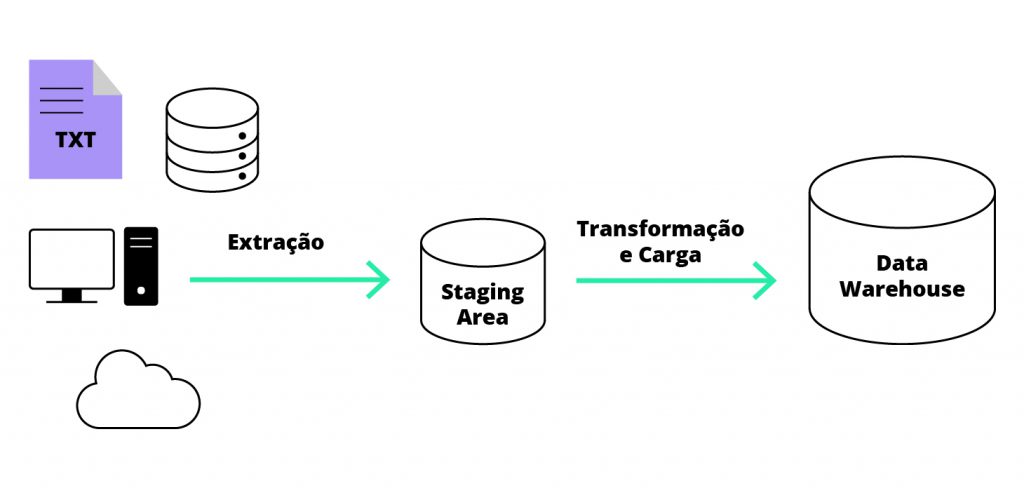
Confira como funciona a divisão do processo de ETL e o que acontece em cada uma das etapas a seguir:
E – Extract
O primeiro estágio do processo de ETL é destinado à coleta de dados e consiste na comunicação com outros sistemas ou banco de dados SQL para capturar informação. Nela, os dados são extraídos dos OLTPs e encaminhados para uma área de transição temporária (staging area), onde são organizados e convertidos para um formato único.
Essa ação inicial tem como objetivo homogeneizar as diferenças existentes nas informações extraídas de diferentes fontes com base em uma análise feita previamente sobre a relevância de cada informação. Esse processo inicial é o que vai permitir que os dados possam ser manipulados nas fases seguintes.
T – Transform
Após a coleta, definição e formatação dos dados a serem incluídos no repositório final, está tudo pronto para que se inicie a etapa de transformação, que é essencialmente sobre a categorização e segmentação desses dados.
Dados oriundos de sistemas diferentes possuem padrões distintos. Por isso, é necessário realizar a limpeza dos dados coletados na fase anterior, bem como a criação de filtros para agrupar informação com base em categorias.
O processo de transformação dos dados deve atender a alguns critérios como limpeza, padronização e qualidade. Aqui é hora de corrigir inconsistências e imprecisões com o objetivo de consolidar a informação obtida.
Parte desse processo é chamado de data mapping, que consiste em indicar em arquivos ou tabelas as correspondências entre campos e valores. Dessa forma, os softwares de ETL podem varrer o documento, analisá-lo e construir relatórios de inteligência.
Os filtros usados para tratar dados na fase de transformação variam de acordo com a necessidade do negócio. Algumas variáveis e procedimentos que ocorrem durante esse processo são:
- Tamanho e tipo de informação
- Substituição de caracteres estranhos
- Correção de erros de digitação
- Comparação fonética para evitar duplicidade
- Substituição de dados não preenchidos por valores neutros
- Unificação de unidades de medida
- Arredondamento de casas decimais
O que se espera ao final dessa etapa é a consolidação de dados com qualidade suficiente para que gere insumos concretos para análise. Tomando como exemplo um departamento de marketing, a ideia é que seja possível visualizar elementos como o perfil do consumidor e, com base nisso, direcionar ações de negócios.
Ao fim desta etapa, espera-se que esteja definida toda a arquitetura de dados a ser extraída dos OTLPs, o tipo de informação que deve alimentar o ambiente de armazenamento final e a qualidade dos insumos a serem carregados na fase posterior.
A transformação dos dados deve ser acompanhada de perto e homologada por especialistas em Data Science e/ou Business Intelligence, pois já nesta fase deve servir de base para a geração de relatórios e gráficos que apoiam tomadas de decisão.
L – Load
Por fim, a etapa final consiste em estruturar os dados para que sejam lidos nas staging areas e enviados para o ambiente de armazenamento escolhido – seja um data warehouse ou data mart.
Esse carregamento deve ser feito de forma que a informação seja mantida organizada, mapeada e acessível, mas esse upload não precisa ser necessariamente realizado em um único ambiente. Os dados podem ser depositados em diferentes aplicações ou na nuvem.
Esse carregamento é programado para ser executado diariamente, geralmente fora dos horários de pico de uso dos sistemas que vão fomentar o data warehouse, à exceção de negócios que exijam a entrada de dados em tempo real.
Por isso, é importante observar o volume de dados e o tempo a ser extraído e transformado para evitar o comprometimento da performance dos sistemas.
Ao fim da fase de carga, espera-se que o material obtido sirva de insumo para o processo de mineração de dados, no qual softwares e algoritmos analisam e encontram padrões sofisticados, impossíveis de serem identificados por seres humanos.
Como realizar o processo de ETL?
Como você viu, ETL é um processo complexo e detalhado. É importante deixar claro também que não necessariamente todas as etapas são executadas em apenas um ambiente de tratamento de informação.
Ao contrário do que pode parecer, isso pode descomplicar as ações, mas exige cautela redobrada na movimentação dos dados e comparação de tabelas para evitar desvios.
Para facilitar esse processo, a vasta maioria das empresas utiliza um amplo universo de ferramentas e aplicações disponíveis no mercado para tratar dados. Algumas vantagens de investir em ferramentas para realizar o processo de ETL são:
- Agilidade de integração de dados
- Escalabilidade
- Segurança operacional
- Aumento de desempenho
- Garantir a qualidade dos dados
- Manutenção dos metadados
Qual a importância do ETL na integração de dados?
O ETL é considerado a peça que dá “inteligência” ao processo de BI e é amplamente conhecido como o fator que define as regras da exploração dos dados no negócio e o elo que possibilita a condução de dados ao ambiente final.
Portanto, o processo de extração, transformação e carga de dados é fundamental para qualquer trabalho de inteligência de dados, principalmente na integração de dados de origens distintas e no tratamento deles sob parâmetros qualitativos – muitas vezes impossíveis de serem aplicados na ferramenta de armazenamento inicial.
Por meio desse cruzamento de dados, o ETL permite uma visão holística de todos os pontos de atenção e variáveis envolvidos no processo de decisão. Sem isso, seria praticamente impossível validar a qualidade dos dados, diminuindo a confiabilidade deles no processo de tomada de decisão de negócios.
Além disso, é possível alimentar data warehouses e data marts com finalidades diferentes simultaneamente, empoderando os processos em todos os setores de uma organização.
Gostou do nosso conteúdo? Entre em contato conosco e descubra como podemos ajudá-lo!
